![[SWEA] D2 - 2005. 파스칼의 삼각형 in 파이썬](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbVx1JC%2FbtrCkKT5sAw%2FFFHJbL5jT9J7M9j0qKEpGk%2Fimg.png)
SW Expert Academy
SW 프로그래밍 역량 강화에 도움이 되는 다양한 학습 컨텐츠를 확인하세요!
swexpertacademy.com
문제
크기가 N인 파스칼의 삼각형을 만들어야 한다.
파스칼의 삼각형이란 아래와 같은 규칙을 따른다.
1. 첫 번째 줄은 항상 숫자 1이다.
2. 두 번째 줄부터 각 숫자들은 자신의 왼쪽과 오른쪽 위의 숫자의 합으로 구성된다.
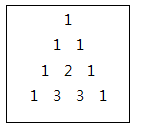
N이 4일 경우,
N을 입력 받아 크기 N인 파스칼의 삼각형을 출력하는 프로그램을 작성하시오.
[제약 사항]
파스칼의 삼각형의 크기 N은 1 이상 10 이하의 정수이다. (1 ≤ N ≤ 10)
[입력]
가장 첫 줄에는 테스트 케이스의 개수 T가 주어지고, 그 아래로 각 테스트 케이스가 주어진다.
각 테스트 케이스에는 N이 주어진다.
[출력]
각 줄은 '#t'로 시작하고, 다음 줄부터 파스칼의 삼각형을 출력한다.
삼각형 각 줄의 처음 숫자가 나오기 전까지의 빈 칸은 생략하고 숫자들 사이에는 한 칸의 빈칸을 출력한다.
(t는 테스트 케이스의 번호를 의미하며 1부터 시작한다.)
입력
4
출력
1
1 1
1 2 1
1 3 3 1
문제 풀이
규칙을 먼저 찾은 뒤 이를 구현하는 방식으로 문제를 풀었다.

N = 4 일 경우,
1. 높이(h)가 1 부터 4 인 노드가 생성된다. (= 높이: 1~N)
2. 각 층의 노드 수는 해당 층의 높이(h)와 같다.
3. 노드의 좌우 양 끝단은 숫자 1로 고정된다.
4. 따라서 양 끝단 사이의 나머지 노드 수는 h-2개이다.
5. h-2개의 노드들은 상위 노드들의 합을 값으로 갖는다.
5-1. 즉, h-2개의 노드들은 각각 1 부터 h-2 까지의 인덱스를 순서대로 갖는다.
5-2. 각 노드들은 순차적으로 상위 노드의 인접하는 두 개의 값들의 합이다.
예) 노드1: sum(0,1) // 상위노드의 0번째 값과 1번째 값의 합
노드2: sum(1,2) // 상위노드의 1번째 값과 2번째 값의 합
......
위와 같은 규칙을 구현하기 위해 이차원 배열을 사용했다.
구현한 코드는 두 가지이다.
작성 코드 - 방법1
(풀이 로직에서 높이 범위는 1~N 이지만, 배열의 인덱스는 0부터 시작하기 때문에 구현 코드에서 높이 범위는 0~N-1)
1. 결과값을 저장할 빈배열을 선언한 뒤,
2. 각 높이 층마다 노드의 리스트를 만들고,
3. 노드 리스트를 결과 배열에 push(파이썬에선 append)해주는 방식으로 구현했다.
def solve(N):
pascal = []
for h in range(0, N):
if h == 0:
pascal.append([1])
elif h == 1:
pascal.append([1,1])
else:
tmp = [1]
for i in range(0, h-1): # 구현 코드에서는 h가 1이 아니라 0부터 시작하기 때문에 h-2가 아니라 h-1
tmp.append(pascal[h-1][i] + pascal[h-1][i+1])
tmp.append(1)
pascal.append(tmp)
return pascal
T = int(input())
for test_case in range(1, T + 1):
N = int(input())
result = solve(N)
print(f'#{test_case}')
for h in range(0, N):
print(*result[h])
작성 코드 - 방법2
보다 간결하게, 그때그때 push할 필요 없이 미리 N*N 배열을 만드는 방식으로 구현할 수도 있다.
def solve(N):
pascal = [[0] * N for _ in range(N)]
pascal[0][0] = 1 # 첫번째 줄 초기화
for h in range(1, N): # 두번째 줄 부터 규칙 적용
for col in range(N):
if col == 0:
pascal[h][col] = 1
else:
pascal[h][col] = pascal[h-1][col-1] + pascal[h-1][col]
return pascal
T = int(input())
for test_case in range(1, T + 1):
N = int(input())
result = solve(N)
print(f'#{test_case}')
for h in range(0, N):
li = [el for el in result[h] if el > 0]
print(*li)
방법 1 vs 방법 2
| 방법 1 | 방법 2 | |
| 메모리 | 58,240 kb | 58,244 kb |
| 실행시간 | 170 ms | 147 ms |
방법 2가 실행시간이 조금 더 짧은 것을 볼 수 있었다.
방법 1은 상대적으로 append 연산이 잦기 때문인 것 같다.
미리 이차원 배열을 선언해놔도 메모리의 차이는 4kb밖에 되지 않으므로, 실행시간을 단축시키는 게 더 이득일 것이다.
코드 길이나 가독성 면에서도 방법 2가 더 낫다고 여겨진다.
따라서 방법 1보다는 방법 2가 조금 더 효율적인 코드로 보인다.
'Problem Solving' 카테고리의 다른 글
| [SWEA] D2 - 2001. 파리 퇴치 in 파이썬 (0) | 2022.05.17 |
|---|---|
| [SWEA] D2 - 1983. 조교의 성적 매기기 in 파이썬 (0) | 2022.05.17 |
| [JS 알고리즘] Toy 6 - sudoku 스도쿠 (0) | 2022.05.16 |
| [JS 알고리즘] Toy 5 - tiling 타일링 (0) | 2022.05.16 |
| [JS 알고리즘] Toy 4 - bubbleSort (0) | 2022.05.16 |